Static Hashtables in PHP
Hashtables are, in PHP, a quintessential data structure. So versatile and performant is the PHP hashtable (commonly referred to in language parlance as an array or associative array) that it is a mainstay in several applicative contexts. Everything from your run-of-the-mill web application (TODO apps, simple blogs, and the like) to an all-powerful language-powered daemon features one or several instances of an array. Hashtables are wholesome structures and are, like the dynamic variables to which they are often assigned, themselves dynamic.
Dynamism is, in this case, a function of amenability to multiple write operations and renders hashtables prone to size changes and the data subsumed in them — to modification. How about the reverse: static hashtables in which none of the subsumed elements change? After all, immutability and variability are antipodes of each other: two halves of a state categorization dyad. A static hashtable is a single-write, multi-read structure that adheres to many of the same technical conventions as a regular hashtable. It features a non-cryptographic hash algorithm and a fixed memory allotment of contiguous allocable slots the placement of data in which is algorithmically determined.
The idea of a static hashtable in PHP is not a foreign concept — and is by no means a novelty. There already exists a cogent (and perhaps more conventional) static hashtable originally designed for PHP 7 and still perfectly usable in newer versions. The implementation described in the text to follow is one I recently developed for PHP that, like its conceptual sibling, is also written in C. Unlike its conceptual sibling, however, the version discussed in the subsequent text — which I will henceforth refer to as SHT — neither creates nor reads efficient binary file representations of static hashtables. It does, however, feature tandem use of the performant xxhash64 algorithm and linear probing addressing scheme.
The xxhash64 Algorithm
A hash function is a one-way function that transforms a bit vector (an array of bits) into another — often smaller bit vector. Non-cryptographic hash functions like xxhash64, which is designed for modern CPUs, are one-way functions best suited to fast lookup in tables. The O(1) algorithmic complexity associated with hashtables is a transitive relationship with the hash function used to generate table indexes and any supplementary collision-mitigating schemes employed in the table design. xxhash64 is potent insofar as providing RAM access-esque speeds and offering collision resistance such that the likelihood of programs that utilize it succumbing to birthday attacks is reduced significantly.
Algorithmically, xxhash64’s design features a disposition toward operating on composite chunks of input as opposed to working on a single input block one byte at a time. Working on multiple blocks minimizes the occurrences of CPU idleness that occur from the sequential flow implied in the latter rubric that characterizes algorithms like FNV and FNV-1a: awaiting the completion of one block transform is often less temporally efficient than processing multiple streams per transformation step. To follow is a schematic of the aforedescribed mechanism.
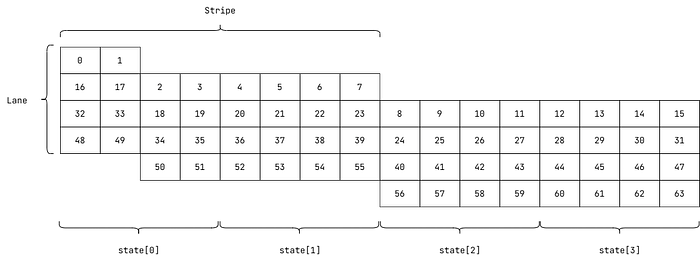
Captured in the image above is the essence of the algorithm: the transformation of an input stream divided into separate states. Transformation is typically a four-step process, as far as hash functions are concerned. The first step is the initialization of an internal algorithmic state which is followed by the splitting of an input (data from which to compute a hash) into even blocks that are combined with the algorithmic state to form a new state in the following phase that culminates in the application of a specialized function to the updated combined state whose output — the hash — is produced in a network of rigorous arithmetic operations that often constitutes some variety of bitwise logics, multiplication, and addition.
xxhash64’s internal state features four accumulators. In the initialization stage, each accumulator is assigned an unsigned 64-bit numeric value. The said values are combined with the input data that is divvied up into 32-bit stripes that are further quadrisected into 8-bit lanes and mixed independently before a final avalanche — a final mix to effect a sensitivity of the final hash to changes in the input and ensure that the final hash reflects a uniform distribution of all preceding state. The result of the process effected by the hash function — its return value — is also an unsigned 64-bit numeric value. To follow is a table that showcases a key-hash mapping — per the implementation of the xxhash64 algorithm in SHT.
+-----------+---------------------+
| input/key | hash |
+-----------+---------------------+
| fold | 5014807915209060508 |
| fork | 5673104366090595873 |
| bar | 5234164152756840025 |
| bat | 2871332559251954573 |
| battery | 5569121457675289045 |
+-----------+---------------------+Linear Probing
The other idea important to the design of SHT is the concept of the linear probe. As mentioned before, linear probing is a means of mitigating collisions in a table. It is an algorithm that complements the afore-elucidated algorithmic computation of table indexes as it is the step that — during insertion, prominently features the placement of an item in a slot and during a key-based search, conditions the retrieval of the correct associative table value. With linear probing, insertion and search intents are contingent on the computation of an index and subsequent ascertainment of the availability of the computed slot. In the forward iteration scheme, the next available slot is only considered in the event of a collision. Take a look at the diagram below.
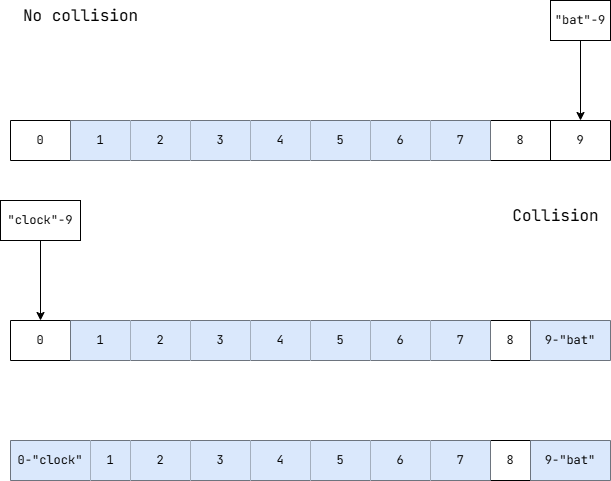
Shown in the diagram above is a list with 10 allocable slots — 7 of which are filled pre-collision; 9 are occupied post-collision. In successive insertion operations, the contents associated with the two keys — “bat” and “clock” — that, per the contrived rules of the example, produce the same hash value — are inserted into the slots numbered 9 and 0 respectively. Pre-collision, the probe conditions the insertion of the data associated with the key “bat” into the vacant slot the index for which matches the computed hash value, 9. Upon ascertaining the occupancy of slot 9 in the subsequent insertion, the algorithm dictates a consideration of the next available slot for the placement of the contents associated with the key “clock”— within the bounds of the array — which is numbered 0. If another right-adjacent slot were available, it would be considered. Such is the forward-iterative nature of the linear probe.
Linear probing is especially sensitive to the result of the hash computation that precedes its invocation. Pairing a hash function like xxhash64 that offers speed and high collision resistance with a linear probing scheme lessens the work done in a linear probe: fewer hash collisions normatively condition fewer iterations in placements and lookups.
SHT’s API is quite simple. It comprises three functions — create, keys, and get. The static create method is a mandatory instantiation function the argument for which is an associative array given the prerequisite for accessing data stored in an instance of the table structure is population. As stated earlier, SHT does not write tables to a binary file (though the feature is an option for the future) but rather, persists them in memory. It is only upon successful operationalization of a table that the access primitives — keys, a function with which to retrieve all keys stored in a table and get, a function with which to access the data associated with a specified key — are deemed usable. The snippet to follow is a demonstration of how to create a static table with the SHT API.
\define('EXIT_FAILURE', 1);
if (!\extension_loaded('sht')) {
echo \sprintf("Please install ext-sht to continue\n");
exit(EXIT_FAILURE);
}
$table = Sht::create(
[
'fold' => 'foo',
'fork' => 12,
'bar' => \range(1, 5),
'bat' => 3.33,
'battery' => 'bar',
],
);
var_dump(
$table->get('bar'), // prints [1, 2, 3, 4, 5]
$table->get('field'), // prints NULL
$table->get('bat'), // prints 3.33
);In conclusion, static hashtables are really just hashtables with a fixed allotment. They are best suited to contexts that require immutability: databases, caches, and the like. The flavor of the static table discussed throughout the text works well on Linux systems and I advise that you peruse the package documentation — and consider using SHT in a project that warrants its inclusion.